La Numérisation
La numérisation du son comporte plusieurs étapes allant de l’origine de la sonorité elle-même à l’écoute du consommateur.
1- Le Son
On peut considérer le son comme une vibration ou une onde de molécules d’air due au mouvement d’un objet. Cette onde est une onde de compression dans laquelle la densité des molécules est plus élevée. L’onde sonore est caractérisée par une fréquence, une longueur d’onde et une amplitude.
La représentation graphique d’une onde permet d’observer des crêtes et des creux d’onde (cf. schéma) .Plus les crêtes et les creux sont proches, plus la fréquence est élevée. Cette fréquence se mesure en Hertz (Hz) et correspond au nombre de cycles par seconde soit f=1/T avec T la période en grandeur de temps. L’oreille humaine perçoit les sons ayant une fréquence comprise entre 20Hz et 20KHz.
La longueur d’onde est la distance entre une compression et la suivante. Plus la longueur d’onde est courte, plus la fréquence est élevée. Elle s’exprime en mètres et correspond à la distance parcourue par l’onde durant une période. Elle se note λ, pour λ=c/f=c*T avec c la célérité de la propagation de l’onde en m.s-1, f la fréquence en Hertz et T la période en secondes.
L’onde sonore contient de l’énergie qui peut être transformée en un autre type d’énergie, comme par exemple l’énergie électrique. Ce principe est notamment utilisé pour les communications téléphoniques.
2- La Captation du Son
Le son émis par une voix ou encore un instrument doit être capté avant d’être numérisé. C’est-à-dire qu’il doit être enregistré. La plupart du temps, on utilise un microphone.
L’onde sonore émise exerce une pression sur la membrane du micro : l’énergie sonore est transformée en énergie mécanique. Par la suite, cette pression est convertie en une variation de tension électrique continue : ce signal est dit analogique.
3- L’Échantillonnage
Le signal analogique obtenu lors de la captation dirigé vers l’ordinateur sera ensuite mesuré plusieurs fois par seconde selon une fréquence d’échantillonnage en Hertz. Une mesure est appelée échantillon ou sample et chacun de ces échantillons possédera une amplitude mesurée en Décibels (db). Plus le nombre d’échantillons (ou samples) est élevé, plus la fréquence d’échantillonnage le sera. La qualité du signal dépendra du nombre d’échantillons prélevés par seconde. C’est en prélevant un maximum d’échantillons que l’on se rapproche le plus du signal analogique de base.
Selon le théorème de Nyquist-Shannon, avoir une fréquence d’échantillonnage deux fois plus élevée que la fréquence maximale contenue dans le son à numériser permet d’éviter des pertes trop importantes. Cependant, il faut rester vigilant à la taille des fichiers qui augmente considérablement lorsque que la fréquence d’échantillonnage est élevée.
4- Quantification
L’échantillonnage nous apporte donc une série d’échantillons possédant chacun une amplitude. Cette série d’amplitude sera ensuite codée en binaire sur un certain nombre de bits. Cette étape correspond à la quantification.
"Codée en Binaire" ? Le codage en binaire correspond à l’écriture d’une information quelconque (ici une amplitude en db) selon le système binaire. Le système binaire est un système de numération utilisant une base binaire (d’où son nom) et exprimant les nombres sous forme de série composées uniquement de 0 et de 1 : c’est la langue de l’ordinateur.
Pour en revenir au son, les amplitudes relevées seront traduites en binaire sur un nombre précis de bits pour être lues par l’ordinateur. Le bit est la plus petite unité d'information manipulable par une machine numérique. Un bit peut être caractérisé par deux états : 0 et 1. Deux bits peuvent donc être caractérisés par 2^2=4 états. Les séries d’amplitudes sont généralement codées sur 8,16 ou encore 32 bits soit respectivement 2^8=256, 2^16=65 536 et 2^32=4 294 967 296 états possibles. Ces états correspondent au nombre de niveaux de quantification (ou paliers) disponibles pour mesure nos amplitudes. On en tire donc inévitablement la conclusion que plus le nombre de bits sera élevé, plus la mesure sera précise.
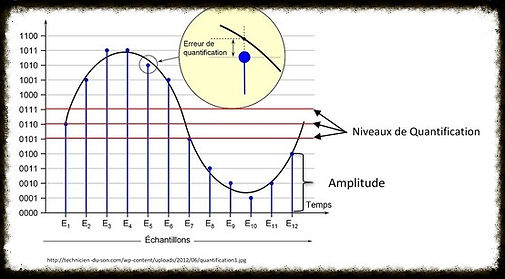
Voici un schéma expliquant cette étape :
La plupart du temps, la valeur réelle de l’amplitude du signal se situe entre deux paliers (cf. schéma) A ce moment-là, on prend le niveau de quantification le plus proche de la valeur exacte : cela donne une erreur de quantification. Pour diminuer le nombre d’erreurs, on code le signal sur un nombre de bits plus grand afin d’avoir plus de paliers.
http://lasciencepourtous.cafe-sciences.org/articles/lacompressiondedonnees/
On peut remarquer que le signal est maintenant en « marche d’escaliers ». On peut encore discerner les différents paliers grâce aux zones horizontales du signal.
5- La Compression
A l’heure de la révolution numérique et l’explosion des sites de téléchargement et de streaming sur internet, la nécessité de réduire au minimum la taille des données utilisées s’est fait ressentir. En effet, les données audio prennent très rapidement énormément de place sur les différents appareils de stockage.
Le « poids » en octet d’un échantillon sonore non compressé se mesure :
poids (octet) = Fréquence d'échantillonnage (Hz) x Résolution (octet) x Durée (seconde) x Nombre de voies
Sachant qu’ 1octet = 8bit et 1kilo-octet (ko) = 1024 octet, prenons comme exemple un échantillon d’une minute de son qualité CD, soit une fréquence d’échantillonnage de 44100 Hz et quantifié sur 16 bits, en stéréo (2 voies). Nous obtenons :
poids (octet) = 44 100 Hz x (16bits/8) octets x 60 secondes x 2 voies
=44 100 Hz x 2 octets x 60 secondes x 2 voies
= 10 584 000 octet
Habituellement, on utilise le Mega-Octet (Mo) pour évoquer le poids des fichiers, donc :
poids (octet) =10 584 000 octet
= 10584000 / 1024 = 10335 Ko
= 10335 / 1024 = 10 Mo
Les morceaux de musique de nos jours durent en moyenne 3 minutes, tandis qu’un album comporte régulièrement 10 chansons. Donc un album avec un son de qualité CD a un poids de :
(10 Mo x 3 minutes) x 12 pistes= 360 Mo
Une taille de données aussi importante est difficile à stocker facilement ou à mettre en ligne, surtout si l’on possède plusieurs albums. Les professionnels du son ont donc trouver une solution : la compression.
La compression est un procédé employé pour réduire le poids des différents fichiers sonores, ou autres. Les compresseurs utilisent un algorithme spécifique au type de fichier compressé : la compression d’une vidéo ou d’un fichier sonore emploiera un algorithme différent. Evidemment, l’opposé du compresseur est le décompresseur, qui permet de restaurer un fichier original à partir d’un fichier compressé.
Il existe deux grands types de compressions : la compression avec pertes de données et la compression sans perte de données.
-La compression avec pertes de données supprime du fichier original des informations parfois superflues tout en essayant de rester au plus près du fichier original. Quelques exemples de format de fichiers compressés avec pertes : le MP3, le AAC ou encore le OGG VORBIS
-La compression sans pertes de données, comme son nom l’indique, compresse le fichier sans supprimer d’informations dans le fichier de base : il est ainsi possible de restaurer le fichier original avec un décompresseur, chose impossible avec une compression avec pertes de données. Quelques exemples de format de fichiers compressés sans pertes : le WAVE, le FLAC ou encore le WMA Lossless.
La grosse différence entre ces deux types de compression est la taille des fichiers compressés : un fichier compressé sans pertes sera beaucoup plus volumineux qu’un fichier compressé avec pertes. En effet, un échantillon sonore compressé en MP3 est dix fois moins volumineux qu’un fichier compressé en WAVE. De quoi laisser de la place pour d’autres albums…